Introduction
ElectrumX is the established Electrum server implementation, written in Python. It processes blocks sequentially on a single thread using asyncio. For standard Bitcoin (BTC) with its 1–4 MB blocks, this design works adequately. However, for high-throughput chains like Bitcoin SV — which routinely produces multi-GB blocks containing billions of transactions across its history — sequential single-threaded processing becomes an insurmountable bottleneck.
ElectrumR is a ground-up rewrite in Rust that parallelizes every stage of block processing. It leverages Rust's zero-cost abstractions, tokio for async I/O, and rayon for CPU-bound parallelism to achieve dramatically higher throughput. The result is an Electrum server capable of 50,000+ transactions per second during sync, support for 50K concurrent client sessions, and a full chain sync that completes in roughly 45 hours instead of 14 days.
This page provides a comprehensive technical deep-dive into every major subsystem of ElectrumR: its architecture, sync pipeline, sharding strategy, memory management, crash recovery, and the optimization journey that shaped its current design.
Architecture
ElectrumR uses a 5-tier agent architecture where each tier handles a distinct responsibility layer, from low-level storage to client-facing protocols. Every tier communicates via well-defined async channels.
+---------------------------------------------------------------+ | Tier 5: Data Access | | QueryRouter (shard-aware) | MerkleAgent (proofs) | +---------------------------------------------------------------+ | Tier 4: Client Protocol | | SessionManager (50K sessions) | ProtocolHandler (JSON-RPC)| +---------------------------------------------------------------+ | Tier 3: Mempool Pipeline | | MempoolSync (ZMQ) | MempoolIndex | FeeEstimator | +---------------------------------------------------------------+ | Tier 2: Block Processing | | SyncManager | Pipeline | BlockFetcher | BlockParser | UTXO | +---------------------------------------------------------------+ | Tier 1: Core Infrastructure | | ShardedDb (RocksDB) | DaemonClient | CacheManager | MemMon | +---------------------------------------------------------------+
Tier 1: Core Infrastructure
The foundation layer. ShardedDb manages 16 RocksDB column families for parallel storage. DaemonClient handles all communication with the bitcoind node (RPC and block file access). CacheManager coordinates the 16-shard UTXO LRU cache and its persistence. MemMon monitors system memory and triggers pressure responses.
Tier 2: Block Processing
The sync engine. SyncManager orchestrates the sync lifecycle (initial sync, ZMQ realtime, polling fallback). Pipeline coordinates the 4-stage pipelined sync. BlockFetcher reads blocks from .blk files or RPC. BlockParser uses rayon for parallel transaction parsing. UTXO handles input resolution and state updates.
Tier 3: Mempool Pipeline
MempoolSync receives real-time transaction notifications via ZMQ. MempoolIndex maintains an in-memory index of unconfirmed transactions. FeeEstimator calculates fee rate estimates from mempool data.
Tier 4: Client Protocol
SessionManager handles up to 50,000 concurrent Electrum client sessions via tokio's async runtime. ProtocolHandler implements the Electrum JSON-RPC protocol, translating client requests into internal queries.
Tier 5: Data Access
QueryRouter routes client queries to the correct RocksDB shard based on the hashX of the address. MerkleAgent constructs Merkle proofs for SPV verification.
ElectrumR vs ElectrumX
A comprehensive comparison between the original Python-based ElectrumX and the Rust-based ElectrumR across every major dimension.
| Aspect | ElectrumX | ElectrumR |
|---|---|---|
| Language | Python 3 | Rust |
| Concurrency | asyncio (single-threaded) | tokio + rayon (multi-threaded) |
| Block Fetching | JSON-RPC only | Direct .blk file reading |
| Sync Architecture | Sequential | Pipelined (fetch→parse→prefetch→apply) |
| Database | LevelDB | RocksDB with 16 shards |
| UTXO Cache | Single-threaded dict | 16-shard LRU with per-shard locks |
| DB Writes | Sequential | Parallel per-shard WriteBatch via rayon |
| Memory Management | Python GC | Manual + adaptive pressure handling |
| Sync Speed | ~1,000–5,000 TPS | 35,000–100,000 TPS |
| CPU Utilization | Single core | All available cores |
Pipelined Sync
ElectrumR's sync engine uses a 4-stage pipeline that overlaps I/O with computation. While one batch of blocks is being applied to the UTXO set, the next batch is having its UTXOs prefetched, the batch after that is being parsed, and the batch after that is being fetched from disk. This ensures that no CPU core or I/O channel sits idle.
+----------+ +----------+ +-------------+ +----------+ | Fetcher |--->| Parser |--->| Prefetcher |--->| Applier | | (async) | | (rayon) | | (async) | | (seq) | +----------+ +----------+ +-------------+ +----------+ Batch N+3 Batch N+2 Batch N+1 Batch N
Stage 1: Fetcher (async I/O)
Reads blocks from bitcoind's .blk files via memory-mapped I/O, or falls back to JSON-RPC when direct file access is unavailable. Blocks are fetched in configurable batch sizes and forwarded to the parser stage via an async channel.
Stage 2: Parser (rayon)
Parallel transaction parsing across all available CPU cores using rayon's work-stealing thread pool. Each block in the batch is deserialized, and all transactions are extracted with their inputs and outputs identified.
Stage 3: Prefetcher (async I/O)
Reads UTXOs from RocksDB for upcoming blocks, warming the 16-shard LRU cache. By the time a batch reaches the applier, the vast majority of its UTXO lookups will be cache hits rather than disk reads.
Stage 4: Applier (sequential)
Sequential UTXO state updates. This stage must be sequential because UTXO spending has strict ordering requirements — a transaction in block N cannot spend an output created in block N+1. The applier processes blocks in height order, updating the UTXO set, writing history entries, and building undo data for crash recovery.
Critical Invariant
Both the fetcher and parser stages sort results by height after par_iter() because rayon returns results in thread scheduling order, not input order. Without this sorting step, blocks with inter-block UTXO dependencies fail — a transaction in block N may reference an output created in block N-1, and if N-1 hasn't been processed first, the input resolution will incorrectly report a missing UTXO.
Direct Block Reading
One of ElectrumR's most impactful optimizations is bypassing bitcoind's JSON-RPC interface entirely for block retrieval. Instead of asking bitcoind to serialize a block as JSON, ElectrumR reads blocks directly from the .blk data files on disk using memory-mapped I/O.
Traditional (ElectrumX): ElectrumX -> JSON-RPC -> bitcoind -> parse JSON -> decode hex -> block data Overhead: ~50-100ms per block, JSON parsing, hex decoding ElectrumR Direct: ElectrumR -> mmap(.blk file) -> block data Overhead: ~0.1ms per block, zero-copy where possible
Benefits
- 100x faster block retrieval compared to JSON-RPC
- Zero JSON parsing — raw binary block data read directly
- Eliminates RPC rate limits — no connection pooling or throttling needed
- Works when bitcoind RPC is slow — independent of bitcoind's request handling
Chain Order Verification
Because .blk files store blocks in the order they were received (not necessarily chain order), ElectrumR must reconstruct the correct chain ordering:
- Scan all .blk files — index block locations by block hash, recording each block's file offset and size
- Build chain by following prev_hash links — starting from genesis, follow each block's
prev_hashpointer to reconstruct the full chain - Sample-based verification against bitcoind RPC — verify every 1,000th block hash, plus every block in the 620k–650k range (a historically contentious region)
- Correct any orphan blocks — identify and exclude blocks not on the longest chain
Performance Note
Chain order is built in ~12 seconds for 870,000+ blocks. The previous approach of verifying every block hash via RPC took over 2 hours.
Parallel Processing
ElectrumR parallelizes as much work as possible across all available CPU cores. The two key parallelized operations are input resolution and database writes.
Input Resolution (3 Phases)
- Identify all inputs — scan every transaction in the batch to collect all inputs that need UTXO resolution (previous tx_hash + output index)
- Parallel resolve via 16-shard UTXO cache — rayon threads look up each input in the sharded cache. Because each shard has its own mutex, threads accessing different shards never contend with each other
- Fall back to RocksDB for cache misses — any inputs not found in the cache are resolved via parallel shard reads from RocksDB, with results inserted into the cache for future use
Per-Shard WriteBatch
Database writes were a major bottleneck when done sequentially. The parallel approach builds and commits 16 independent WriteBatch objects simultaneously:
Sequential (old): Build 1 WriteBatch -> write all 16 shards -> done Parallel (new): Build 16 WriteBatch in parallel -> write 16 shards in parallel -> done
The parallel approach reduces write latency significantly because each shard's WriteBatch only contains operations for that shard, and all 16 writes execute concurrently on separate rayon threads.
UTXO Cache
The UTXO cache is a 16-shard LRU cache that stores unspent transaction outputs in memory for fast lookup. It is the single most important data structure for sync performance — cache hits are orders of magnitude faster than RocksDB lookups.
Persistence
The cache is persisted to disk on shutdown and restored on startup. This avoids the catastrophic cold-start problem where a freshly launched server has 0% cache hit rate.
Shutdown: Saved 94,385,923 UTXO cache entries in 15s Startup: Loaded 94,394,880 entries in 33s (2.8M entries/sec)
Entry Format
Each cache entry is 63 bytes:
| Field | Size (bytes) | Description |
|---|---|---|
tx_hash |
32 | Transaction hash |
tx_idx |
4 | Output index within the transaction |
hashx |
11 | Truncated hash of the scriptPubKey |
tx_num |
8 | Global transaction sequence number |
value |
8 | Output value in satoshis |
Impact
Without persistence, every restart begins with a 0% hit rate, causing 10–30x slower sync until the cache warms up. With persistence, the cache immediately provides >97% hit rate on restart, making continued sync virtually indistinguishable from a server that never stopped.
Memory Management
ElectrumR implements a 4-level adaptive memory pressure system that prevents out-of-memory crashes by progressively reducing workload as memory usage increases.
| Level | Threshold | Action |
|---|---|---|
| Normal | <60% | Full speed — no restrictions on batch size or processing |
| Warning | 60–75% | Reduce batch size by 50% to slow memory growth |
| Critical | 75–85% | Reduce batch size by 75%, force flush pending writes to disk |
| Emergency | >85% | Pause sync entirely, flush all pending data, wait for memory to drop |
malloc_trim Throttling
Early profiling revealed that malloc_trim() — called to return freed memory to the OS — was consuming 4.5% of total CPU time. This was because it was being called too frequently. The fix was simple: throttle malloc_trim() calls to 60-second intervals. Memory is still returned to the OS, but without the constant CPU overhead.
Large Block Handling
Bitcoin SV can produce blocks exceeding 1 GB. Three mechanisms work together to handle these safely:
- Adaptive batch sizing — blocks larger than 256 MB automatically set
batch_size=1, processing the block alone without batching - Total batch memory cap — the
SYNC_MAX_BATCH_MEMORY_MBsetting (default 2048) limits the total memory consumed by any single batch of blocks - Memory headroom gate — before fetching a batch, the system estimates whether there is at least 6x the raw block size available as memory headroom (to account for parsed data structures, UTXO lookups, and write buffers)
Crash Recovery
ElectrumR tracks a flushed_height that represents the last block height whose data has been durably committed to RocksDB. On startup, if the current height exceeds the flushed height, the server knows a crash occurred between processing and flushing, and can rewind using undo data.
if state.height > state.flushed_height { // Crashed between processing and flushing // Rewind using undo data rewind_to(state.flushed_height); }
Undo Data
Each block flush writes undo entries that record the state changes made by that block. Each undo entry is 60 bytes and includes the full tx_hash for hash index restoration. The format is backward compatible with the older 24-byte format used before hash index support was added.
On crash recovery, undo entries are replayed in reverse order (from highest flushed height down to the target rewind height), restoring each spent UTXO and removing each created UTXO, effectively un-doing the block's effects on the database.
ZMQ Notifications
ElectrumR supports three sync modes, automatically transitioning between them based on how far behind the chain tip the server is and whether ZMQ is available.
| Mode | Description | Trigger |
|---|---|---|
| InitialSync | File-based pipelined sync using direct .blk reading | 12+ blocks behind chain tip |
| ZmqRealtime | ZMQ push notifications for instant block processing | <12 blocks behind, ZMQ connected |
| PollingFallback | RPC polling every 5 seconds for new blocks | ZMQ unavailable or connection failed |
bitcoind Configuration
ElectrumR uses the ZMQ v2 topics (hashblock2 and rawblock2) for improved reliability:
zmqpubhashblock2=tcp://127.0.0.1:28332 zmqpubrawblock2=tcp://127.0.0.1:28332
Safety Features
- Flush before mode switch — all pending data is flushed to disk before transitioning between sync modes, ensuring no data is lost during the switch
- prev_hash verification — every incoming block's
prev_hashis verified against the last known block to detect chain reorganizations - Sequence gap detection — ZMQ sequence numbers are monitored; if a gap is detected (missed notification), the server falls back to RPC polling to catch up
TUI Monitor
ElectrumR ships with a real-time terminal user interface (TUI) monitoring dashboard that provides at-a-glance visibility into sync progress, cache performance, memory usage, and server health.
$ ./target/release/electrumr-monitor
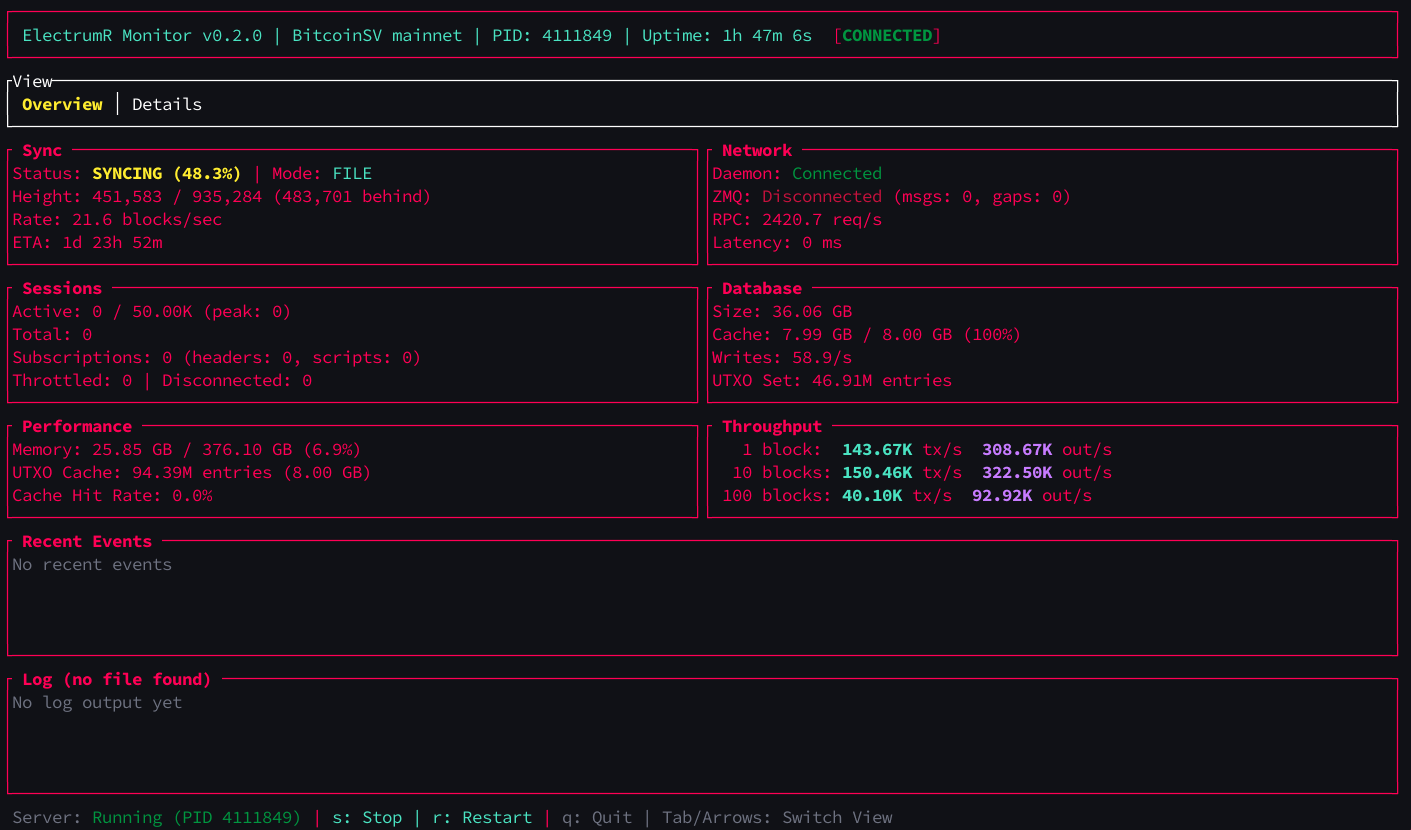
The monitor connects to the running ElectrumR instance via a Unix socket stats endpoint and displays live metrics including current block height, transactions per second, UTXO cache hit rate, RocksDB statistics, memory pressure level, and active client session count. It updates continuously and is safe to run alongside the server with no performance impact.
BSV-Specific Considerations
Bitcoin SV has several consensus differences from BTC that affect how an Electrum server must index outputs. ElectrumR handles all of these correctly:
- OP_RETURN outputs are spendable — unlike BTC where
OP_RETURNmarks an output as provably unspendable, BSV allows these outputs to be spent. ElectrumR indexes them as regular UTXOs. - Empty scriptPubKey outputs are spendable — outputs with a zero-length scriptPubKey are valid and spendable on BSV. ElectrumR does not skip them during indexing.
- All outputs are indexed — the internal
is_unspendable()function returnsfalsefor all outputs on BSV. No output is skipped during UTXO set construction, ensuring complete coverage of the chain state.
Why This Matters
If an Electrum server skips indexing OP_RETURN or empty-script outputs on BSV, it will fail to resolve inputs that spend those outputs. This causes sync failures, incorrect balance calculations, and missing transaction history for affected addresses.
Optimization History
ElectrumR's performance is the result of 12 distinct optimization phases, each building on the last. The following table documents every major change and its measured impact.
| Phase | Optimization | Impact |
|---|---|---|
| 1 | Batch & cache tuning (fetch batch 10→128, flush 100→200) | 10–15x throughput |
| 2 | Flush coalescing (4 I/O ops → 1 atomic batch) | ~2x throughput |
| 3 | Pipeline architecture (overlapped fetch/parse/apply) | ~2x throughput |
| 4 | Crash recovery (flushed_height + undo data) | Reliability |
| 5 | RPC-free block hash lookup (chain order from .blk files) | Eliminates RPC bottleneck |
| 6 | Flamegraph tuning (malloc_trim, compression, compaction) | 2–3x throughput |
| 7 | Sample-based chain verification (2+ hours → ~1.4 seconds) | 5000x faster startup |
| 8 | Parallel per-shard WriteBatch (rayon) | Reduced write latency |
| 9 | UTXO cache persistence (save/load 94M entries) | 10–30x restart speed |
| 10 | Startup compaction (auto-compact L0 files) | Prevents restart slowdown |
| 11 | Parallel input resolution (rayon + sharded cache) | Reduced lock contention |
| 12 | 16-shard UTXO LRU cache (per-shard mutexes) | Eliminates cache contention |
Flamegraph Tuning
Flamegraph profiling revealed four major CPU bottlenecks that were not obvious from code review. Each was addressed with a targeted fix:
| Bottleneck | CPU % | Fix |
|---|---|---|
malloc_trim |
4.5% | Throttle to 60-second intervals instead of calling on every flush |
LZ4_compress_fast_continue |
4.3% | Disable LZ4 compression during initial sync (re-enable after sync) |
RocksDB CompactionIterator |
3.4% | Disable auto-compaction during sync (run manual compaction at startup) |
RocksDB MemTable::KeyComparator |
3.4% | Larger write buffers, relaxed L0 file count triggers |
Together, these four fixes reclaimed over 15% of CPU time that was being spent on overhead rather than actual block processing. The result was a 2–3x improvement in sustained sync throughput.
Storage Schema
ElectrumR uses RocksDB with 16 column families (shards). All keys are binary-packed for space efficiency. The following key formats are used across the database:
UTXO Keys
// Key: prefix(1) + tx_hash(32) + tx_idx(4) = 37 bytes b'U' + tx_hash[32 bytes] + tx_idx[4 bytes BE] // Value: hashx(11) + tx_num(8) + value(8) = 27 bytes hashx[11 bytes] + tx_num[8 bytes BE] + value[8 bytes BE]
History Keys
// Key: prefix(1) + hashx(11) + tx_num(8) = 20 bytes b'H' + hashx[11 bytes] + tx_num[8 bytes BE] // Value: empty (key-only entry) // The tx_num in the key is sufficient to look up the full tx
HashX Index Keys
// Key: prefix(1) + tx_hash(32) = 33 bytes b'X' + tx_hash[32 bytes] // Value: tx_num(8) = 8 bytes tx_num[8 bytes BE]
Undo Keys
// Key: prefix(1) + height(4) = 5 bytes b'Z' + height[4 bytes BE] // Value: variable-length array of undo entries // Each entry: 60 bytes (with tx_hash for hash index restoration) // Backward compatible with older 24-byte format
State Metadata
// Stored in the default (non-sharded) column family b"state" -> { height: u32, // Current processed height flushed_height: u32, // Last durably flushed height tx_count: u64, // Total transactions indexed tip_hash: [u8;32], // Current chain tip block hash db_version: u32, // Schema version for migrations }